By Steve Endow
This is a long post, but I think the context and the entire story help paint a picture of how things can fail in unexpected and odd ways, and how storage failures can be more complicated to deal with than you might expect. I learned several lessons so far, and I'm still in the middle of it, so I may learn more as things unfold.
On Tuesday evening, I received several emails from my backup software telling me that backup jobs had failed. Some were from Veeam, my absolute favorite backup software, saying that my Hyper-V backups had failed. Others were from Acronis True Image, saying that my workstation backup had failed.
Hmmm.
Based on the errors, it looks like both backup apps were unable to access my Synology NAS, where their backup files are stored.
That's odd.
When I tried to access the UNC path for my Synology on my Windows desktop, I got an error that the device could not be found. Strange.
I then opened a web browser to login to the Synology. But the login page wouldn't load. I then checked to make sure the Synology was turned on. Yup, the lights were on.
After several refreshes and a long delay, the login page eventually loaded, but I couldn't login. I then tried connecting over SSH using Putty. I was able to connect, but it was VERY slow. Like 30 seconds to get a login prompt, 30 seconds to respond after entering my username, etc. I was eventually able to login, so I tried
these commands to try and reboot the Synology via the SSH terminal.
After issuing the command for a reboot, the power light started blinking, but the unit didn't shutdown. Strangely, after issuing the shutdown command, I was able to login to the web interface, but it was very slow and wasn't displaying properly. I eventually had to hold the power button down for 10 seconds to hard reset the Synology, and then turned it back on.
After it rebooted, it seemed fine. I was able to browse the shares and access the web interface. Weird.
As a precaution, I submitted a support case with Synology asking them how I should handle this situation in the future and what might be causing it. I didn't think it was a big deal.
On Wednesday evening, I got the same error emails from my backup software. The backups had failed. Again. Once again, the Synology was unresponsive, so I went through the same process, and eventually had to hard reset it to login and get it working again.
So at this point, it seemed pretty clear there is a real problem. But it was late and I was tired, so I left it and would look into it in the morning.
On Thursday morning, the Synology was again unresponsive. Fortunately, I received a response from Synology support and sent them a debug log that they had requested. Within 30 minutes I received a reply, informing me that the likely issue was a bad disk.
Apparently the bad disk was causing the Synology to deal with read errors, and that was actually causing the Synology OS kernel to become unstable, or "kernel panic".
This news offered me two surprises. First, I was surprised to learn that I had a bad disk. Why hadn't I known that or noticed that?
Second, I was surprised to learn that a bad disk can make the Synology unstable. I had assumed that a drive failure would be detected and the drive would be taken offline, or some equivalent. I would not have guessed that a drive could fail in a way that would make the NAS effectively unusable.
After reviewing the logs, I found out why I didn't know I had a bad drive.
The log was filled with hundreds of errors, "Failed to send email". Apparently the SMTP authentication had stopped working months ago, and I never noticed. I get so much email that I never noticed the lack of email from the Synology.
The drive apparently started to have problems back in July, but up until this week, the Synology seemed to still work, so I had no reason to suspect a problem.
Synology support also informed me that the unit was running a "parity consistency check" to try and verify the data on all of the drives. This process normally slows the unit down, and the bad drive makes the process painfully slow.
After a day and a half, the process is only 20% complete, so this is apparently going to take 4-5 more days.
So that's great and all, but if I know I have a bad drive, can't I just replace the drive now and get on with the recovery process? Unfortunately, no. Synology support said that I should wait for the parity consistency check to complete before pulling the bad drive, as the process is "making certain you are not suffering data/ volume corruption so you can later repair your volume with no issues."
Lovely. So waiting for this process to complete is preventing me from replacing the bad drive that is causing the process to run so slowly. And I'm going to have to wait for nearly a week to replace the drive, all the while hoping that the drive doesn't die completely.
I'm sensing that this process is less than ideal. It's certainly much messier than what I would have expected from a RAID array drive failure.
But that's not all! Nosiree!
In addition to informing me that I have a bad drive that is causing the Synology to become unusable, it turns out that I have a second drive that is starting to fail in a different manner.
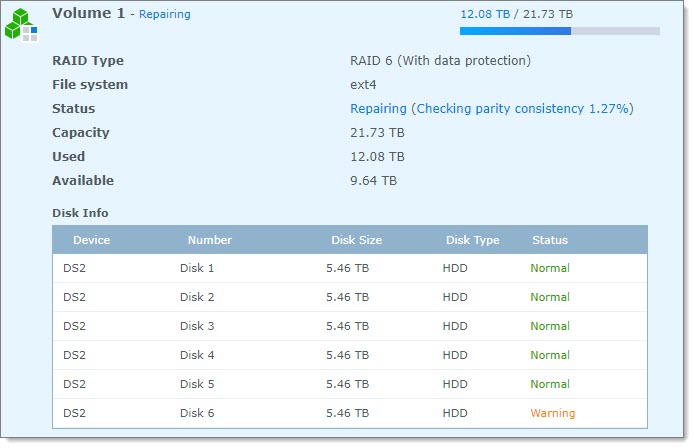
Notice that Disk 6 has a Warning status? That's actually the
second bad drive. The first bad drive is Disk 2, which shows a nice happy green "Normal" status.
After reviewing my debug log, Synology support warned me that Disk 6 is accumulating bad sectors.
Sure enough, 61 bad sectors. Not huge, but a sign that there is a problem and it should probably be replaced.
Lovely.
So why did I not know about this problem? Well, even if SMTP had been working properly on my Synology, it turns out that the bad sector warnings are not enabled by default on the Synology. So you can have a disk failing and stacking up bad sectors, but you'd never know it. So that was yet another thing I learned, and I have now enabled that warning.
Correction 1: I remembered that the monthly disk health report shows bad sectors, so if you have that report enabled, and if your SMTP email is working, you will see the bad sector count--assuming you review that email.
Correction 2: A reader noted that new Synology units or new DSM installs apparently do have the Bad Sector Warning notification enabled by default, and set with a default of 50 bad sectors as the threshold. But if you have an existing / older Synology, it likely does not have the Bad Sector Warning enabled.
So, here's where I'm at.
I've fixed the email settings so that I am now getting email notifications.
I'm 20% into the parity consistency check, and will have to wait 5+ more days for that to finish.
As soon as I learned that I had 2 bad drives on Thursday morning, I ordered two replacement drives. I paid $50 for overnight express shipment with morning delivery. Because I wanted to replace the drives right away, right? But that was before Synology emphasized that I should wait for the parity check to complete. So those drives are going to sit in the box for a week--unless a drive dies completely in the meantime.
If the parity check does complete successfully, I'll be able to replace Drive 2, which is the one with the serious problems. I'll then have to wait for the Synology to rebuild the array and populate that drive.
Once that is done, I'll be able to replace Drive 6, and wait for it to rebuild.
Great, all done, right?
Nope. I'll need to hook up the two bad drives and run the manufacturer diagnostics and hopefully get clear evidence of an issue that allows me to RMA the drives. Because I will want the extra drives. If I can't get an RMA, I'll be buying at least 1 new drive.
This experience has made me think differently about NAS units. My Synology has 8 drive bays, and I have 6 drives in it. The Synology supports hot spare drives, so I will be using the additional drives to fill the other two bays and have at least one hot spare available, and most likely 2 hot spares.
Previously, I didn't think much of hot spares. If a drive fails, RAID lets you limp along until you replace the bad drive right? In concept. But as I have experienced, a "drive failure" isn't always a nice clean drive death. And this is the first time I've seen two drives in the same RAID array have issues.
And it's also shown me that when drives have issues, but don't fail outright, they can make the NAS virtually unusable for days. I had never considered this scenario. While I'm waiting to fix my main NAS, my local backups won't work. And this Synology is also backing up its data to Backblaze B2 for my offsite backup. That backup is also disabled while the parity check runs. And I then have another on-site backup to a second Synology unit using HyperBackup. Again, that backup is not working either. So my second and third level backups are not available until I get my main unit fixed.
Do I redirect my backup software to save to my second Synology? Will that mess up my backup history and backup chains? I don't know. I'll have to see if I can add secondary backup repositories to Veeam and Acronis and perhaps merge them later.
Another change I'll be making is to backup more data to my Backblaze B2 account. I realized that I was only backing up some of the data from my main Synology to B2. I'll now be backing up nearly everything to B2.
So this has all been much messier than I would have imagined. Fortunately it hasn't been catastrophic, at least not yet. Hopefully I can replace the drives and everything will be fine, but the process has made me realize that it's really difficult to anticipate the complications from storage failures.
Update: It's now Monday morning (9/11/2017), 5 full days after the Synology was last rebooted and the parity consistency check was started, and it's only at 31%. I did copy some files off of this unit to my backup Synology, which seems to pause or stop the parity check, but at this speed, it's going to take weeks to finish. This long parity processing does seem to be a result of the bad Drive 2, as the parity consistency check recently ran on my other Synology in under a day.
Update 2: Tuesday morning, 9/12/2017. The parity consistency check is at 33.4%. Painfully slow. My interpretation is that any task, job, process, or file operation on the Synology seems to pause or delay the parity consistency check. I have now disabled all HyperBackup jobs, paused CloudSync, and stopped my Veeam backup jobs to minimize activity on the limping Synology. I may turn off file sharing as well, just to ensure that network file access isn't interfering with the parity check process.
I also just noticed that the File Services settings on the Synology show that SMB is not enabled. My understanding is that this is required for Windows file sharing, so I'm puzzled how I'm still able to access the Synology shares from my desktop. I didn't turn it off, so I'm not sure if this is due to the Synology being in a confused state due to the drive issues, or something else. I find it strange that my backup software is unable to access the Synology shares, but I'm able to eventually access them--although they are very slow to come up.
Update 3: Monday, 9/18/2017 - The Saga Continues: After thinking about it, I realized that the parity consistency check was likely triggered because I powered off the Synology before it shut down on its own. At the time, I thought that the unit was hung or unresponsive, but I now realize that it was the bad disk that was causing the shutdown to take forever. The parity check is estimated to take 2-4 years due to the bad drive, so I just shut the unit down to replace the bad drive. It took 30-60 minutes for it to fully power down. If you encounter an issue with a drive that causes the Synology to be slow or seem unresponsive, avoid doing a hard reset or hard shutdown on the unit. Try the shutdown command and wait an hour or two to see if the shutdown eventually completes on its own. This will hopefully allow you to avoid a parity consistency check, which is a major hassle with a bad drive.
Now that I've replaced the drive and powered the Synology on, the parity consistency check is still running, and I'm unable to add the replacement disk to my volume. I've replied to Synology support on my existing case asking them how to cancel the parity consistency check and just add the replacement drive so that it can get started on the volume repair process.
Update 4: 9/18/2017: After replacing the bad drive, I see that the parity consistency check is running much faster and I may not have to cancel it. With the bad drive, the process was estimated to take 2-4 years (yes YEARS) to complete, but with the new drive, it is currently estimating about 16 hours. I'm going to let it run overnight and see how much progress it has made by tomorrow morning.
Update 5: 9/19/2017: The parity consistency check finally completed and the Synology began to beep every few seconds, indicating that the volume was "degraded".
Since the parity check was no longer running, the "Manage" button became active, and I was able to add the new drive to the volume and start the repair process, which was quite simple.
So the repair process is now running and it looks like it will take about 26 hours to complete.
Update 6: 9/20/2017: The repair process appears to be going well and should complete today.
While the repair is running, I plugged the bad drive into my desktop and ran the HGST "DFT for Windows" diagnostic application to test the drive. Interestingly, it is not detecting any problems. On the extended tests, it appears to be hanging, but it isn't identifying a problem.
Final update: 9/22/2017: I replaced the second bad drive and the Synology has repaired the volume. Things are back to normal and working well.
I created RMAs for both of the HGST hard drives and mailed them back, so I should get replacements for those drives, which I'll install in the Synology as hot spares.
Steve Endow is a Microsoft MVP in
Los Angeles. He is the owner of Precipio Services, which provides
Dynamics GP integrations, customizations, and automation solutions.